
 下载APP
下载APP 报料
报料 关于
关于
光明网 2026-06-05 15:30:14
设想这样一个场景:你在追一个刚刚转过街角的人。视线被建筑物挡住了,你看不见他。但你的大脑并不会因此陷入茫然,你听到了脚步声的方向,你记得他刚才的速度,你对街道的格局有直觉性的判断。于是你判断出他可能在哪个方向,加快步伐转过拐角。
这个看似平常的瞬间,其实完成了一次极其复杂的“多感官融合推理”:视觉、听觉、空间记忆,被大脑整合成一个连贯的行动判断。
然而,机器人一旦面对类似场景,却往往陷入失灵,它的每个传感器各自运转,但它不知道该如何把它们整合起来。
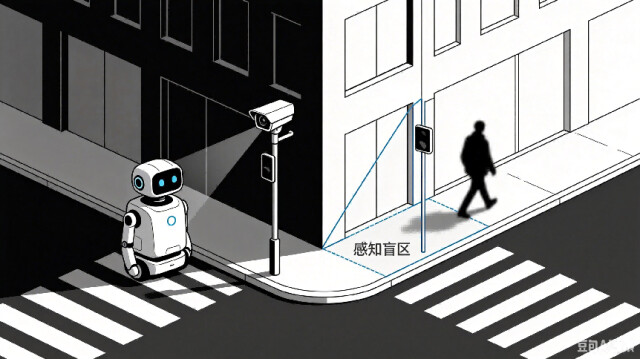
单一感官的局限
再精良的传感器,单独使用时都有盲区。
视觉摄像头能看清正前方,却看不到身后;激光雷达能精准测距,却无法识别物体的语义(那是一只猫,还是一个纸箱?);麦克风能捕捉声音,却无法判断声源的精确空间位置。
就如同蒙住一只眼睛判断距离,或者捂住耳朵辨别方向,单独依赖任何一种感知,都会造成严重的信息缺失。
多模态融合感知(Multimodal Fusion Perception)正是为了解决这个问题而生的技术方向:将来自不同传感器、不同频段、不同时序的信息进行整合与协同处理,通过信息互补,提升智能系统对复杂环境的整体理解、推理和决策能力。
第一类融合:时空几何融合——搞清楚“我在哪里”
机器人要行动,面临的第一个关键问题是空间定位:机器人在哪里?周围有什么?彼此之间的空间关系如何?
解决这类问题的,是几何-空间状态融合技术。其核心目标,是将多视角的传感器信息融合进统一的三维几何空间,构建出带有实时三维坐标的“语义体素地图”。
BEV(鸟瞰视角)感知以及在此基础上演进的Occupancy Grid(占用网络),是其中最具代表性的方案。它将来自多种传感器,包括摄像头、激光雷达、毫米波雷达等异构数据,统一投影到一个从上向下俯瞰的坐标系中。这种自上而下的视角,消除了各个传感器特有的视角畸变与盲区,使系统能够准确感知和理解物体间的空间关系,大幅降低多视角数据融合的复杂度。
无人驾驶汽车是这项技术最成熟的应用场景。车辆四周布置的摄像头和雷达,将数据汇入BEV坐标系,让自动驾驶系统能够一目了然地“看到”周围车辆、行人和障碍物的精确位置,而不是碎片化地拼凑来自不同方向的传感器数据。

多模态融合的“全景视角”
第二类融合:语义-视觉表征融合——搞清楚“这是什么”
空间定位解决了“在哪里”的问题,但还远远不够,机器人还需要理解它感知到的东西究竟是什么,以及它背后意味着什么。
这是语义-视觉表征融合技术要解决的问题。
传统的图像识别算法,通常只能做分类:这是苹果,那是香蕉。但一张真实场景的图像包含的信息远不止于此,物体的状态、位置关系、动作含义,都需要被理解。
语义-视觉表征融合,将图像、视频等视觉信息与文本标签、知识图谱等语义信息转化为统一的数学特征向量空间,使计算机既能“看懂”图像,又能“理解”其背后的逻辑与概念。
视觉语言大模型(VLM)是这一技术的集中体现。它能够同时处理图像和文本,根据图像生成描述性文字,回答关于图像内容的问题,乃至根据文字描述生成图像。
具体到机器人应用:当机器人看到一个装满热水的玻璃杯时,VLM不仅能识别出“玻璃杯”,还能理解“杯子放在桌子上”“里面有液体、容易打翻、需要轻拿轻放”“冒着热气可能比较烫”。这种语义层面的理解,是机器人能够安全、得体地执行操作的前提。
第三类融合:主动交互式感知——主动出击,预判未来
前两类融合,多少带有“被动接收”的性质——等待信息输入,然后处理。但人类在真实世界中的感知,往往是主动的:我们会主动转头寻找声音来源,会主动靠近看不清的东西,会根据已知情况预判接下来可能发生什么。
主动交互式感知融合,正是赋予机器人这种“主动感知、动态预判”能力的技术。它要解决的核心问题是:如何更主动、更高效地获取动态环境中的信息。

主动交互式感知
这类系统要求智能体具备主动视觉感知与推理能力:能够理解场景中的三维物理关系,预测复杂任务的执行路径,甚至在主动探索中更新对环境的认知。
一个典型应用,是机器人的自主目标搜索:机器人需要在未知环境中找到某个物体,不是漫无目的地乱转,而是基于实时环境反馈动态调整搜索策略——看到了书桌,判断书可能在这附近;没找到,转而搜索下一个高概率区域。这种“感知-预判-行动-再感知”的动态实时闭环,是主动感知融合的核心机制。
三类融合,织就智能的感知网
这三类多模态融合感知技术,分别对应了不同层次的认知需求:
几何-空间融合(物理层):我在哪,周围有什么,彼此的空间关系如何?
语义-视觉融合(认知层):这是什么,意味着什么,该如何处理?
主动交互融合(行为层):下一步该看向哪里,预判什么,主动做什么?
就像追拐角的那个人:你用耳朵(听觉)判断声音方位(空间融合),用常识分析那个人还在奔跑,不可能凭空消失(语义融合),用经验预判他下一步可能往哪个方向跑(主动预判)。这三者缺一不可,共同构成了人类瞬间完成的综合感知推理。
具身智能机器人正在习得同样的能力。这条路尚未走完,但方向已然清晰。
(本文系浙江大学教授、博士生导师、浙江大学具身智能感知与控制实验室(ZEAL Lab)负责人、中国仪器仪表学会科普专家、浙江省仪器仪表学会监事长侯迪波在“智感世界·仪创未来”系列科普直播之从感知到控制:读懂具身智能新科技的主题分享,光明网记者肖春芳整理)
责编:李传新
一审:李传新
二审:段涵敏
三审:文凤雏
来源:光明网
我要问
 湘公网安备 43010502000374号
湘公网安备 43010502000374号